「RAG」とは?概要と簡易的な構築手順を解説!
2025年4月8日

こんにちは!オルトロボでエンジニアとして働くSです。
今回は、最近話題の「RAG」について、概要の説明と簡易構築手順を解説します。
目次
1.RAGとは?
RAG(Retrieval-Augmented Generation)は、「検索拡張生成」と訳されるテクノロジーで、自然言語処理においてAIが情報を生成する際に、データベースや文献などの外部情報源から関連情報を検索し、その情報を統合してより精度の高い回答や内容を生成する手法です。
この技術は、特に情報の正確性が求められる質問応答システムや、詳細なデータが求められるテキスト生成において有効です。
◆RAGの活用例
医療情報の提供
医療分野では、診断支援システムや病歴解析ツールにRAGが使用されています。
たとえば、患者の症状や医療履歴に基づき、関連する医学文献や研究データから情報を検索し、診断提案や治療方法に関する詳細情報を生成します。
法律アドバイザリー
法律分野において、顧客の具体的な法的問題に対して適切な法規情報や過去の裁判例を検索し、専門的なアドバイスを生成するためにRAGが使用されます。これにより、弁護士や法務部門が効率的に情報を処理し、迅速な法的支援を提供することが可能になります。
学術研究支援
研究者が特定の学問領域に関する最新研究を探求する際に、関連する学術論文やデータベースから必要な情報を検索し、研究概要や文献レビューを生成するなどでRAGが使用されます。
カスタマーサポートとエンゲージメント
企業のカスタマーサポートでは、顧客の問い合わせに対して、関連する製品マニュアルやFAQから最適な解答を検索し、具体的で役立つ情報を生成して顧客対応の質を向上させるためにRAGが使用されます。
RAGを使用しない場合、LLMの知識ベースに依存するため情報が古くなったり、知識がなかったりするため、正しくない情報を出力する可能性があります。その結果、LLMを使用する意味がなくなり、AIで出来ることを人の手で行わなければならず、効率が大きく低下します。
RAGを使用することで、上記のような問題を解決することができ、業務の質やユーザの満足度を大きく向上させることができます。
.
◆RAGの動作プロセス
1.問題解析:ユーザーからのクエリや問題が与えられます。
2.情報検索:クエリに関連する情報を外部のデータベースや文献から検索します。
3.情報統合:検索された情報を基にして、AIが回答や内容を生成します。
2.RAGの利点
①高精度な回答生成
関連する情報源から直接情報を取得し、それをもとに回答を生成するため、生成される内容の精度が高くなります。
②幅広い分野での応用
医療・法律・科学研究・カスタマーサポートなど、さまざまな分野で活用できます。
③ユーザー満足度の向上
精度の高い詳細な回答を提供できるため、エンドユーザーはより質の高いサービスを受けられ、満足度が向上します。
④時間とリソースの節約
大量の情報源から必要な情報を迅速に取得し、それを統合して回答を生成することで、業務の効率化が図れます。
3.RAGの課題
①情報源の質による影響
情報源の質が悪いと生成される回答の精度が下がります。異なる情報源から矛盾する情報が得られた場合、どのように対応するのかが課題となります。
②処理負荷と応答速度
外部データベースから情報を検索し統合するプロセスは大量のリソースを消費します。そのため処理が完了するまでの時間が長くなる可能性があり、リアルタイムでの応答が求められる場合には適さないかもしれません。
③情報の更新とメンテナンス
情報が古くなる場合には、継続的に情報のアップデートとメンテナンスが必要です。そのためシステムが複雑になる可能性があります。
4.RAGを構築してみよう!
RAGについて理解できたところで、実際に簡単なRAGを構築してみましょう。
今回はチャットシステムの構築は行わず、RAG部分のみ構築をします。
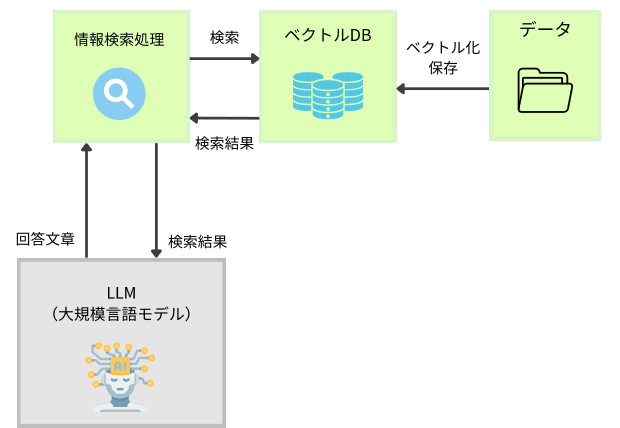
以下が、処理の流れと今回作成する処理の概要図です。
◆処理の流れ
①インプットデータをベクトル化しベクトルDBへ格納します。
②検索を行い、必要な情報を取得します。
③検索で取得した情報をLLMへ渡し、回答を生成します。
|以下は使用するものです
・Python 3.13.2
・Visual Studio Code
・インプットデータ: LLMに出力させたオルトロボ学校(空想)の校則です
・ベクトルDB: Weaviate 1.29.1
・Embeddingモデル(ベクトル化モデル): cl-tohoku/bert-base-japaneseを使用します
・LLM(大規模言語モデル): OpenAI gpt-4
それでは、実際に構築していきます。
4-1 環境構築
以下の環境を構築していきます。
4.1.1. Weaviate (ベクトルDB)の構築
4.1.2 Python仮想環境の構築
4.1.1. Weaviate (ベクトルDB)の構築
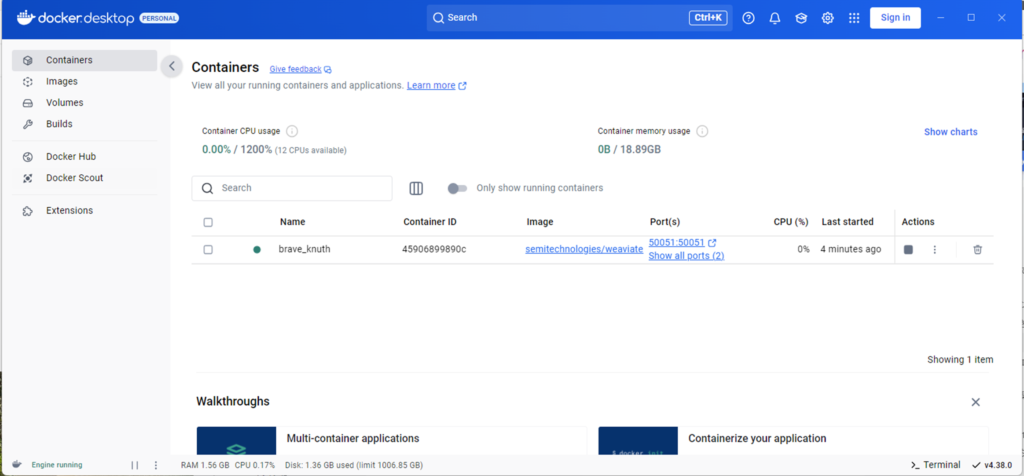
今回は、Dockerコンテナ上にWeaviateを提供されているデフォルト設定を利用して構築します。
コマンドプロンプトを起動し、以下コマンドを実行します。

Dockerを確認すると、コンテナが追加されています。
これで、ベクトルDBの構築・開始が完了しました。
なお、コマンドプロンプトを終了するとWeaviateが終了します。
4.1.2 Python仮想環境の構築
RAGを構築するために、Pythonの仮想環境を準備します。
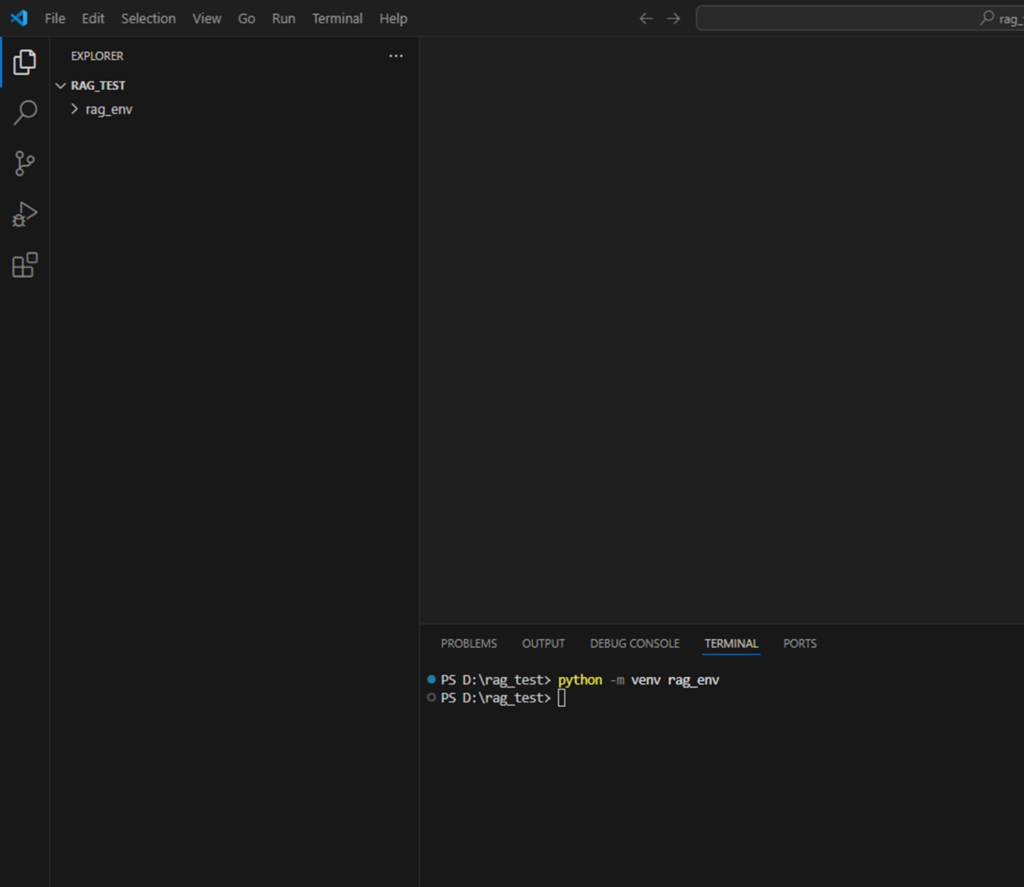
まず、任意の場所にフォルダを作成し、作成したフォルダをVscodeで開きます。
「ctrl + @」でターミナルを表示し、以下のコマンドで仮想環境を構築できます。
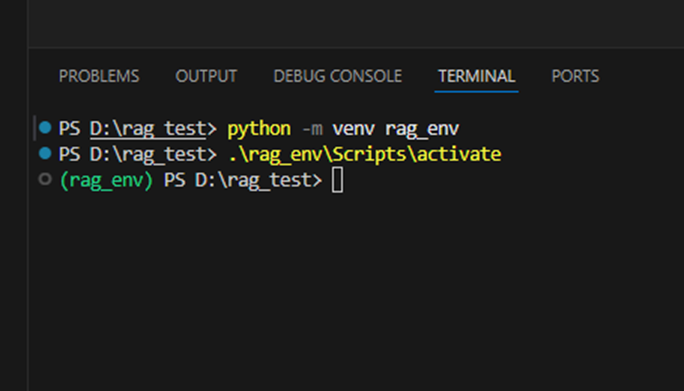
上記コマンドで作成されたフォルダ内の、activateを実行することで、仮想環境を有効化できます。
必要なパッケージをインストールします。
pip install fugashi
pip install transformers
pip install unidic-lite
pip install weaviate-client
pip install dotenv
これでPython環境の構築は完了です。
4-2. 実装
今回使用するインプットデータは、LLMに出力させた「オルトロボ学校(空想)」の規則です。
今回は、各セクションで区切った文字列をベクトル化していきます。
-
1. 始業時間:
授業は毎朝8時30分に始まります。全校生徒は始業15分前には教室に着席している必要があります。時間厳守を促進するため、教室への入室は8時15分から可能です。 -
2. 終業時間:
授業は毎日午後3時30分に終了します。しかし、水曜日は週に一度の大掃除のために午後4時30分に終業となります。部活動や補習は終業後に行われ、参加する生徒は活動終了30分以内に帰宅することが求められます。 -
3. 頭髪規定:
男子:前髪:眉にかからない長さ /色:自然な髪色(ブラックまたはダークブラウン) /形状:極端に立てたり、逆立てるスタイルは禁止
女子:前髪:眉が隠れない長さ /色:自然な髪色(ブラックまたはダークブラウン) /形状:肩より長い髪は結んで整える -
4. 服装規定:
男子:制服:紺ブレザー、グレーのズボン /ソックス:黒または紺色の長さはくるぶしより上 /マフラー:校色の紺と白のストライプ
女子:制服:紺ブレザー、チェック柄のスカート /ソックス:白のニーソックス /マフラー:校色の紺と白のストライプ
共通:コート:ダークカラーのシンプルなデザイン /カバン:革製またはダークカラーの布製 / 靴:黒の革靴 ネックレス、ピアス、指輪、ブレスレット、ベルト:授業中はすべての装飾品の着用禁止 /指導を受けた場合:校則違反のアイテムは没収し、保護者への通知とともに返却 -
5. 通学規定:
自転車、徒歩、公共交通機関を利用して通学する生徒は、安全規則を守ることが必須です。特に自転車通学の生徒はヘルメット着用を義務付けます。 -
6. アルバイト規定:
生徒は学業に支障がない範囲で週に最大10時間までアルバイトが許可されます。アルバイトは学校に登録し、成績が平均以上であることが条件です。 -
7. テスト期間中規定:
テストの一週間前からは、補習授業や自習のために学校は毎日午後5時まで開放されます。この期間中はアルバイト禁止とし、集中的な学習が求められます。 -
8. 校内生活規定:
校内では高声を避け、走らないこと。教職員や来客に対しては礼儀正しく振る舞うことが求められます。 -
9. 校内美化規定:
生徒は自分の使用した教室や施設は清掃する責任があり、ゴミは分別して指定の場所に捨てます。 -
10. 携帯電話規定:
授業中の携帯電話の使用は禁止されています。緊急時を除き、学校では電源を切るかマナーモードに設定すること。 -
11. 校外生活規定:
学生服を着用している場合は、学校の代表として振る舞う必要があります。不適切な場所での目撃は校則違反とみなされます。 -
12. いじめ規定:
いじめを目撃した場合は直ちに教員に報告すること。いじめは厳重に対処され、繰り返し行われた場合は退学処分も含まれる可能性があります。 -
13. 男女交際規定:
公然とした過度のスキンシップや学業に影響を及ぼすような行動は禁止されています。交際に関しては節度を持って行動すること。 -
14. 欠席・遅刻規定:
欠席や遅刻は事前に保護者から学校へ連絡が必要です。無断欠席や遅刻は成績に影響するほか、指導を受けることがあります。
上記のインプットデータを、data.txtファイルでもっておきます。
srcフォルダを作成し、以下3つのファイルで構成します 。
…テキストデータをベクトルデータに変換します。
・insert_vector_db.py
…ベクトルDBへデータを格納します
・search_and_generate.py
…質問内容に似た情報をベクトルDBから検索取得し、LLMへ渡し回答を得ます
|各ファイルの内容
◆embedding.py
テキストをベクトル化する処理です。
def embedding(text):
# 使用するモデル名
model_name = “cl-tohoku/bert-base-japanese”
# トークナイザー(テキストをトークンに分割するためのツール)を初期化
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
# BERTモデルを初期化
model = BertModel.from_pretrained(model_name)
# トークナイザーでテキストをモデルが理解できる形式に変換
inputs = tokenizer(text, return_tensors=’pt’, padding=’max_length’, max_length=512)
# ベクトル化
outputs = model(**inputs)
# 最後の隠れ層の出力を取得し、その平均値から文全体のベクトルを生成
embeddings = outputs.last_hidden_state.mean(dim=1).detach().numpy()
return embeddings.toList()[0]
◆insert_vector_db.py
テキストをdata.txtから取得し、ベクトル化を行い、ベクトルDBに保存するまでの処理です。
import weaviate
from weaviate.classes.config import Property, DataType
filename = ‘data.txt’
lines = []
collection_name = “rag_test”
# ファイルを開いて1行ずつ読み込む
with open(filename, ‘r’, encoding=’utf-8′) as file:
for line in file:
# 各行をリストに追加
lines.append(line.strip()) # strip() で行末の改行文字を除去
# weaviateクライアントの生成
weaviate_client = weaviate.connect_to_local()
# 初期化
weaviate_client.collections.delete(collection_name)
# コレクションの作成
weaviate_client.collections.create(
collection_name,
properties=[
Property(name=”text”, data_type=DataType.TEXT)
]
)
# コレクションの取得
collection = weaviate_client.collections.get(collection_name)
for line in lines:
# 文字列をベクトル化
vector = embedding.embedding(line)
# ベクトルをDBへ保存
uuid = collection.data.insert(
properties={
“text”: line
},
vector=vector
)
print(uuid)
weaviate_client.close()
◆search_and_generate.py
質問内容をベクトル化し、ベクトルDB内のベクトルと比較することで類似度の高いテキストを取得します。
取得したテキストを情報としてLLMへ渡すことで、回答を取得します。
LLM出力を行うにはOpenAI のAPIキーが必要なため取得し、環境ファイル(.env)に入力しておきます。
import weaviate
from weaviate.classes.query import MetadataQuery
import os
from dotenv import load_dotenv
from openai import OpenAI
# 環境ファイル参照
load_dotenv(‘.env’)
collection_name = “rag_test”
# 質問
question = “オルトロボ学校には何時までに行けばいいですか?”
# 質問のベクトル化
vector = embedding.embedding(question)
# Weaviateクライアント生成
weaviate_client = weaviate.connect_to_local()
# コレクションの取得
collection = weaviate_client.collections.get(collection_name)
# ベクトル検索
response = collection.query.near_vector(
near_vector=vector,
limit=3,
return_metadata=MetadataQuery(distance=True)
)
# 結果取得
result_text_list = []
for o in response.objects:
print(o.properties)
print(o.metadata.distance)
result_text_list.append(o.properties[“text”])
weaviate_client.close()
# OpenAI クライアント生成
openai_api_key = os.environ[“OPENAI_API_KEY”]
openai_client = OpenAI(
api_key=openai_api_key
)
# LLMへの指示
prompt = “「” + question + “」に対する回答を以下の情報を元に生成してください\n\n” + “\n”.join(result_text_list)
# LLM回答生成
completion = openai_client.chat.completions.create(
model=”gpt-4″,
messages=[
{ “role”: “user”, “content”: prompt}
]
)
print(completion.choices[0].message.content)
5.RAGによるLLM出力の比較
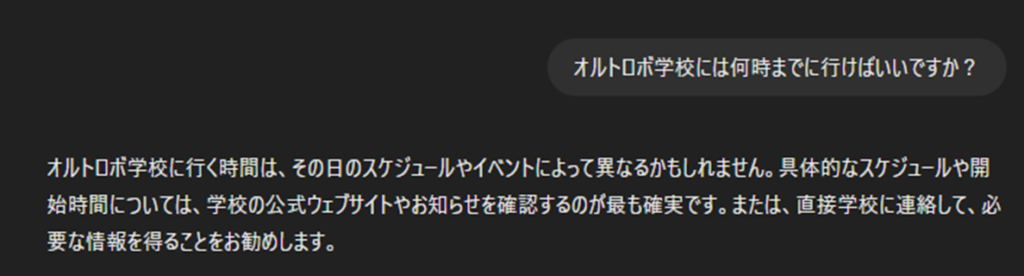
質問1:オルトロボ学校には何時までに行けばいいですか?
|RAGなし
|RAGあり

RAGなしでは「かもしれません」という憶測があり、直接学校へ連絡して確認てほしいと言われています。
RAGありでは、ベクトル検索の時点で3つの類似度の高いテキストを取得しています。その中に該当の始業時間に関する情報があったため、LLMがオルトロボ学校の生徒に対して正しい回答を出力することができています。
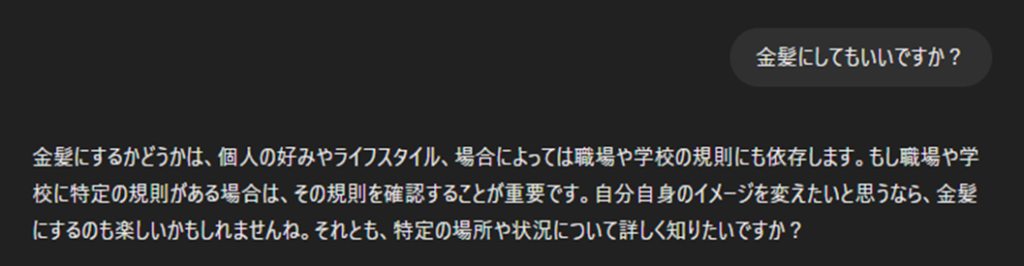
質問2:金髪にしてもいいですか?
|RAGなし
|RAGあり

RAGなしでは、個人の自由だから好きにして良いとのことです。
RAGありでは、ベクトル検索によって頭髪規定を取得できているため正しい回答が得られています。
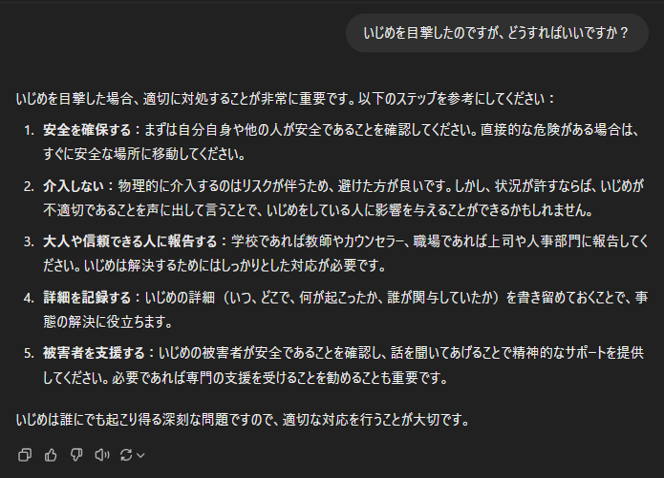
質問3:いじめを目撃したのですが、どうすればいいですか?
|RAGなし
|RAGあり

RAGなしでは、丁寧にいじめの対処法を説明してくれています。
RAGありでは、ベクトル検索によっていじめ規定を取得できたので、オルトロボ学生に対しての正しい回答が得られています。
しかし、ベクトル検索で取得した関係のない規定をもとに「いじめの場面が教室や施設であった場合、校内規定に基づき清掃する責任があります」など関係のないことまでLLMが出力してしまっています。
6.結果
RAGを使用した場合、オルトロボ学校の正確な始業時間や学校の頭髪規定について、ベクトル検索によって直接関連情報が取得され、具体的かつ正確な回答が可能となります。
また、いじめを目撃した際の適切な対処法に関する情報も、学校の規定として取得することができました。
これはRAGの大きな利点である「関連する情報源から直接情報を取得し、それをもとに回答を生成する」という特性がうまく機能している例です。
しかし、いじめの場面においては、RAGによって関連性の低い情報(いじめが発生した場所の清掃責任についての規定など)も取得してしまい、その結果として無関係な情報が回答に含まれることがありました。
これは、外部データベースから情報を検索し統合する際に、情報源の質や関連性が問題となる点であり、一般的に指摘されているRAGの課題と一致します。
情報源が不適切であると、生成される回答の精度が下がり、誤った情報が提供されるリスクがあります。
したがって、RAGの導入は大きな利点をもたらす一方で、課題も浮き彫りになっています。課題に対する効果的な対策を講じることが、RAG技術をより実用的にするためには重要です。
7.まとめ
以上、RAGの概要と、その簡易構築手順についてお話ししました。
簡易構築とはいえ、環境のセットアップからベクトルデータベースの使用まで、手順が多くなりました。
しかし、RAGは多様な用途に適用できるため、試してみる価値は大いにあると思います。
今後は、入力データの質を向上させるために形態素解析を行ったり、ベクトル検索の精度を高めるためにファインチューニングを施すなど、新しい技術に触れることで、RAGだけでなく他のシステムにも応用できる可能性があります。ぜひ挑戦してみてください。
また今後、ベクトル検索の精度において、どのベクトル化モデルが精度が高くでるか検証した記事を執筆予定です。
最後までお読みいただき、誠にありがとうございました!